⚙️ Kubernetes Config
Welcome to the core of Kubernetes deployment logic. Now that you’ve seen how APIs move from OpenAPI
spec to live deployments via AKS, we’re going one layer deeper; into the configurations that drive scaling, security, routing, and resilience. This section explains how Kubernetes manifests shape real infrastructure.This isn’t just about writing YAML; it’s about architecting predictable systems. When you define a Deployment
, you're scripting the lifecycle of your services. When you bind an Ingress, you're deciding how users will find your app. And when you tune your Horizontal Pod Autoscaler, you're directly influencing cloud cost and performance.You'll explore how configs cascade; how a ConfigMap
is mounted as an environment variable, or how a Secret informs pod startup. You'll see how configs get injected, tested, validated, and most importantly, how they evolve. And you'll learn to manage them like code, complete with versioning and rollbacks.Whether you're deploying stateless microservices, running long-lived workers, or wiring up service meshes, configuration is the common denominator. Done right, it becomes a single source of truth; done wrong, it becomes the silent root of outages. This section gives you the mindset, vocabulary, and muscle memory to avoid the latter.
⚙️ Interactive YAML Playground
To explore how YAML shapes deployment behavior, use the interactive playground below:
apiVersion: v1
kind: Service
metadata:
name: my-api
spec:
selector:
app: my-api
ports:
- protocol: TCP
port: 80
targetPort: 3000
Use the interactive playground above to compare base vs production-ready YAML configurations. Hover over any field for guidance, and notice how things like livenessProbe, envFrom, and strategy impact behavior.
YAML is both a structure and a philosophy; declarative, readable, and portable. It lets teams define infrastructure in the same way they define code, tested, linted, and version-controlled. A minor misconfiguration in a readinessProbe or a missing resource limit can lead to unstable deployments or autoscaling failures. In production, understanding each block isn’t optional; it’s mission-critical.
What makes a YAML config production-ready? Strong defaults, clear metadata, consistent labels, and modularity. You'll see these practices reflected in Helm charts and Kustomize bases. Start building the habit now of writing your YAML as if another engineer will inherit it tomorrow; because they often will.
📈 API Lifecycle Recap Timeline
- OpenAPI Spec
- Postman Testing
- Redoc Documentation
- AKS YAML Config
- GitOps CI Pipeline
- AKS Deployment
This horizontal timeline breaks down the journey from API spec to deployment, connecting each concept we’ve explored so far. The timeline reinforces sequencing; from writing your OpenAPI spec
, testing with Postman, documenting in Redoc, to deploying using AKS with GitOps workflows. If you’ve followed this path, you’re building skills parallel to actual DevOps pipelines used by top tech companies.Understanding the relationship between code, infrastructure, and documentation is what makes a DevOps engineer truly effective. This timeline visually compresses that journey; showing that infrastructure is not a separate stage, but a continuous part of development.
📊 Visual Flow: From Swagger to AKS Pods
Before diving into the specifics of Kubernetes resources like ConfigMaps
or RBAC, it’s important to understand how everything comes together from a workflow standpoint. This visual overview provides the connective tissue; how a static OpenAPI spec becomes a dynamic containerized service through configuration and automation.Most workflows begin with a Swagger JSON
pushed to GitHub, where infrastructure as code is stored and monitored. From there, CI/CD tools and GitOps platforms detect changes, inject environment variables, validate YAML templates, and deploy into an AKS Cluster. This means your documentation isn't just informative; it powers real deployments.These flows illustrate how declarative GitOps and procedural CI/CD strategies complement each other. Declarative GitOps ensures your cluster state matches what's defined in YAML; procedural CI/CD ensures validations and tests are passed before anything is applied. Together they provide auditability, speed, and confidence.
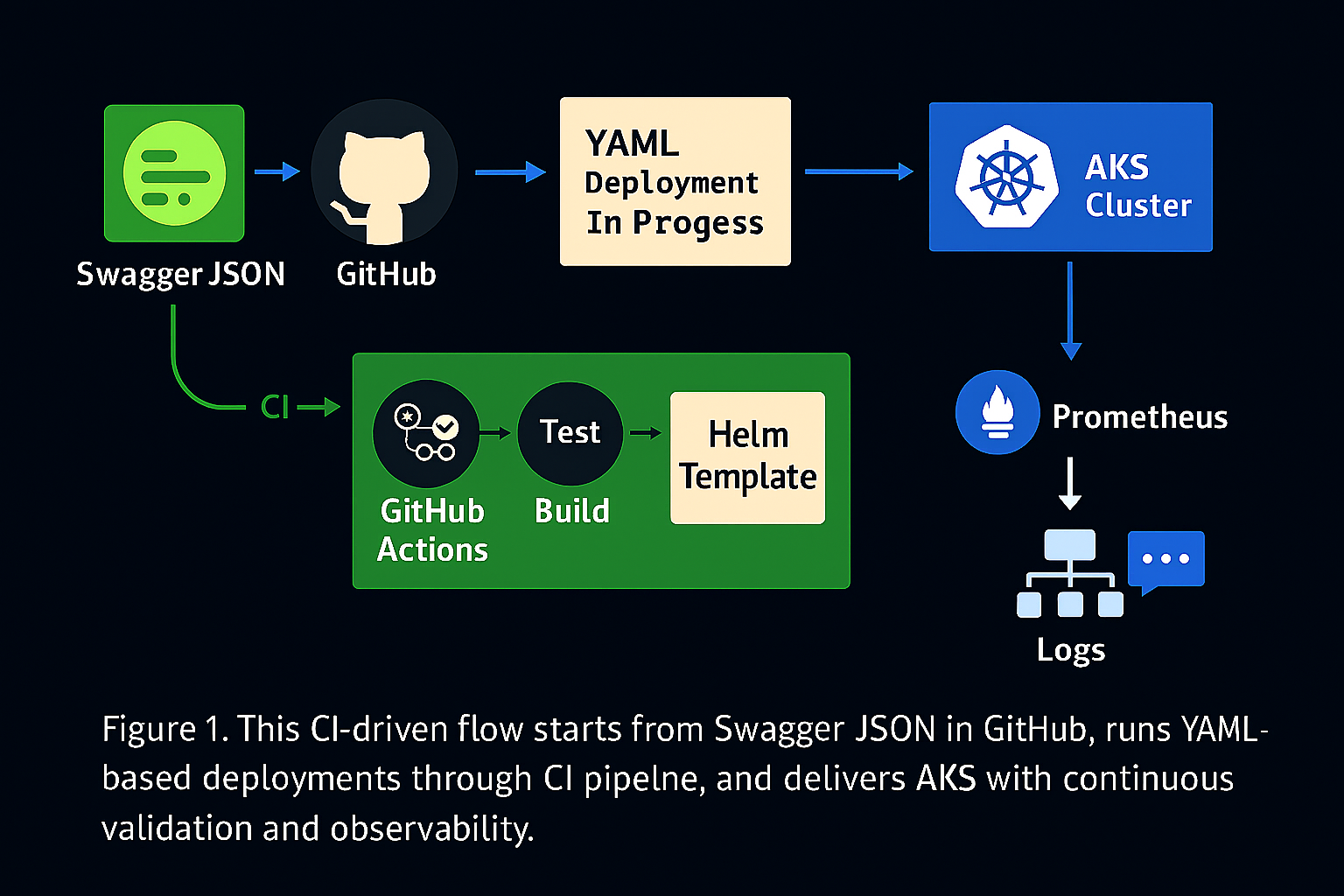
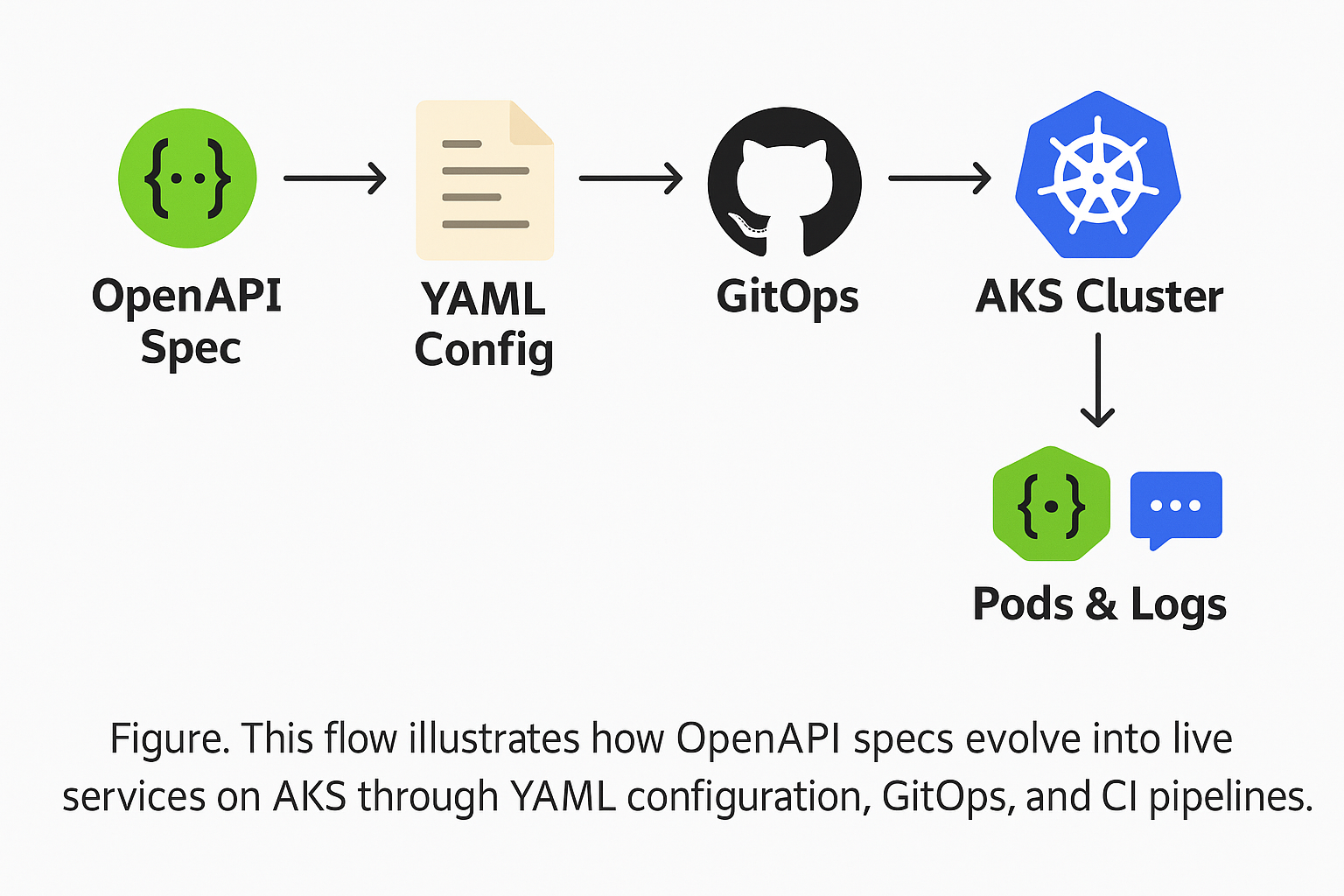

Figure 3. This annotated YAML snippet breaks down the anatomy of a Kubernetes Deployment manifest. Each field—from replicas to readinessProbe—directly controls aspects of scaling, rollout strategy, config injection, and traffic gating. Understanding how these fields affect runtime behavior is essential to mastering Kubernetes operations.
Together, these visuals demonstrate the full lifecycle of API-to-infrastructure workflows: from CI/CD pipelines that enforce quality gates, to GitOps flows that simplify delivery, all the way down to the declarative YAML controlling pod behavior. Whether you're managing services manually or automatically, these patterns reflect real-world DevOps practices used across top engineering teams.
Together, these flows represent the complete YAML lifecycle; defined, committed, validated, and deployed—powering every API instance in your cluster.
Both flows demonstrate how OpenAPI and Swagger specs become part of an infrastructure automation story; either via CI pipelines that test and deploy, or GitOps systems that sync declarative YAML to production. Whether you’re using ArgoCD
, FluxCD, or integrating Azure DevOps and GitHub Actions, the key takeaway is this: YAML is the universal language of Kubernetes, and automation is its backbone.This is where DevOps becomes tangible. You’re no longer writing theory; you’re controlling how real services scale, secure themselves, and recover from failure. And every line of config contributes to that orchestration. You’ll begin to recognize reusable patterns like Helm values, ingress rules, and RBAC bindings that are standard across cloud-native platforms.
🧠 Summary & 📦 What’s Next
You’ve now explored the full infrastructure journey; from defining your API in an OpenAPI spec, templating Kubernetes manifests, and triggering deployments via GitOps or CI/CD. But writing YAML alone doesn’t guarantee uptime, resilience, or secure execution. The real power of Kubernetes lies in the patterns that give your configuration meaning.
So far, you've built the scaffolding; deployments, services, autoscalers, and ingress rules. Now it’s time to strengthen the core mechanics that keep everything running; health checks, access policies, and runtime scaling behaviors. These patterns aren't just optimizations; they’re essential safeguards against downtime, security risks, and runaway costs.
In the next section, we’ll explore exactly how Kubernetes implements these behaviors through tools like RBAC, Probes, Secrets, and Horizontal Pod Autoscalers. You'll learn how to use them together to create self-healing, secure, and intelligently scaling clusters; the traits of every great production-grade system.
Let’s go deeper into what makes Kubernetes production-ready; the operational patterns behind every deployment.